25 novembre 2024, histoire des fantômes

Après avoir choisi la façon de re-programmer et réorganiser la base de données, je voudrais faire un aparté sur l’encodage latin1_swedish_ci. L’encodage c’est le principe de la casse typographique
De l’italien cassa (caisse), la casse est une boîte plate, en bois, à rebords peu élevés, en forme de tiroir et divisée en de nombreux compartiments inégaux appelés cassetins et dont les dimensions sont proportionnelles à la fréquence d’utilisation des lettres ; il ne vous sera pas difficile de trouver le cassetin le plus grand. Cette boîte tiroir permet de ranger l’ensemble d’une police de caractères en plomb. Divisée en deux parties, il y avait le haut de casse où l’on trouvait toutes les capitales et signes divers, et le bas-de-casse réservé aux minuscules, aux chiffres et aux espaces— Source.
En informatique, il faut pouvoir associer un code binaire à une forme visuelle, et ranger toutes ces formes en mémoire pour les rendre accessibles par ce code : les prendre dans leur cassetin, leur case. Comme si l’on numérotait chacun des cassetins d’un tiroir en bois. Un des premiers encodages, ASCII (American standard code for information interchange) s’écrivait sur 7 bits, et l’on pouvait encoder 128 caractères de 0 à 127 [1] Ces 128 premiers caractères conservent leurs codes à travers les futures versions qui, utilisant plus de bits peuvent encoder un plus grand nombre de caractères. Le code 65 est le A majuscule, le 66 représente le B, etc. On a nos cases comme ça jusqu’au tilde de code 126 [2]. Au-delà de 127, les encodages sur 8 bits, puis sur 16 bits, ont dévié chacun de leur côté, avec autant de caisses de bois différentes. Et si l’on passe d’un encodage à l’autre, le caractère 128 par exemple, le premier d’une séquence en 8 bits, sera non défini en latin1_swedish_ci car le cassetin est resté vide pour une raison quelconque, mais représentera le caractère € de l’UTF-8. Plus complexe, il arrive que l’encodage erroné provoque l’affichage de 2 caractères, parce que le code tombe à cheval sur deux cassetins, croyant interpréter de l’UTF-8 [3] le système découpe à tort un caractère en deux parties et en décale une, voilà comment on se retrouve avec un fantôme de caractère, dédoublé, projetant une ombre erronée, et il faut remplacer :
- á par á
- À par - ê par ê
...
latin1_swedish_ci : créé en 1995 par Michael Widenius dit "Monty", David Axmark et Allan Larsson, trois suédois (swedish) développant pour l’Europe occidentale (latin1), et voulant intégrer des lettres tells que Å, Ä, et Ö à une époque pré-UTF-8 des temps jadis. Le "ci" final étant pour "case insensitive", encore plus mystérieux.
Version de Poésies choisies archivée par Internet Archive
Voilà, je trouve Poésies Choisies avec ce problème d’affichage des caractères spéciaux UTF-8, sur des bases créées à l’époque (avant 2004) avec l’encodage latin1_swedish_ci qui ne supportent pas la mise à jour de la base de données MySql 8. Sauf dans certains cas, ce qui est encore plus troublant.
Je reprogramme le système qui, à chaque poème consulté par l’internaute, pour chacun des mots (verbes, noms, adjectifs), va chercher en base, un des poèmes contenant ce mot, pour créer un lien cliquable invisible. Il faut essayer, vouloir toucher le mot pour découvrir qu’il mène à un autre texte. À chaque visite, la requête qui cherche les mots identiques entre les poèmes en prend un au hasard. Une fois, le mot cliquable sera boue, une autre fois ce sera trou.
Ma solution semble un peu lente, il faudra que j’optimise quelque chose, l’index des mots. Ai-je exagéré en stockant les 144 000 et quelques déclinaisons de mots du français ? Ceci pour cibler, mieux que par la taille du mot, les mots portant un "sens", la liste contient les conjugaisons, pluriels, etc., et leur mot source dans sa forme canonique (verbe à l’infinitif, adjectif sans nombre ni genre etc.) M’inspirant d’une des tables du site d’origine [4], j’ai éliminé les déterminants, adverbes, nombres, etc., pour réduire cette liste à 120 154 formes.
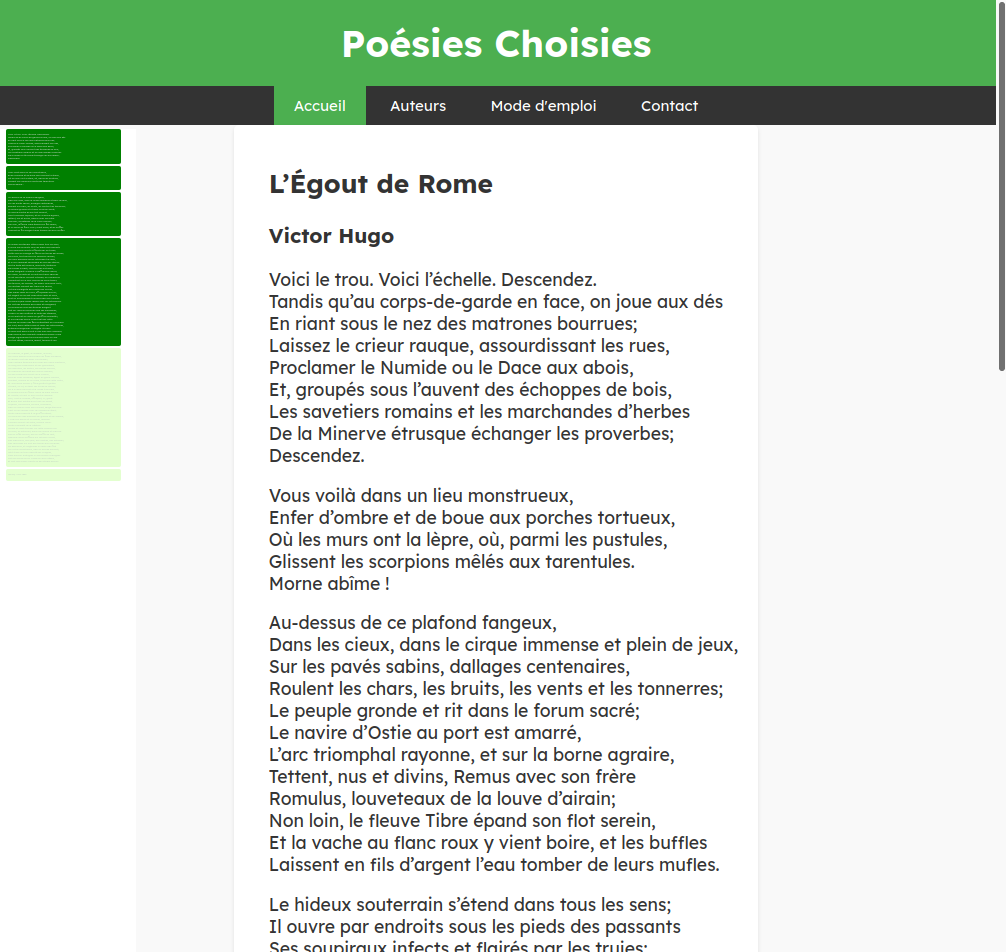
Le même poème dans la nouvelle version
Je reprogramme aussi le fantôme du poème, à gauche, sorte d’ascenseur amélioré où l’on voit les strophes, et celles affichées à l’écran s’allument progressivement, celles qui disparaissent s’éteignent. Ce qui est étonnant, c’est que le logiciel d’écriture de code informatique que j’utilise, Visual Studio Code, sous Linux, utilise exactement ce procédé pour permettre de se repérer dans de longs programmes. Cet écho est assez fascinant, je ne sais pas quel est le premier logiciel de programmation à avoir eu cette idée, qui combine l’ascenseur et le plan des pages (façon Acrobat Reader ou Microsoft Power Point). Peut-être Sublime Text, dès 2008, par Jon Skinner. Des idées identiques peuvent surgir à différents endroits, en différents esprits ayant les mêmes problématiques, la programmation et la poésie n’étant pas si différentes.
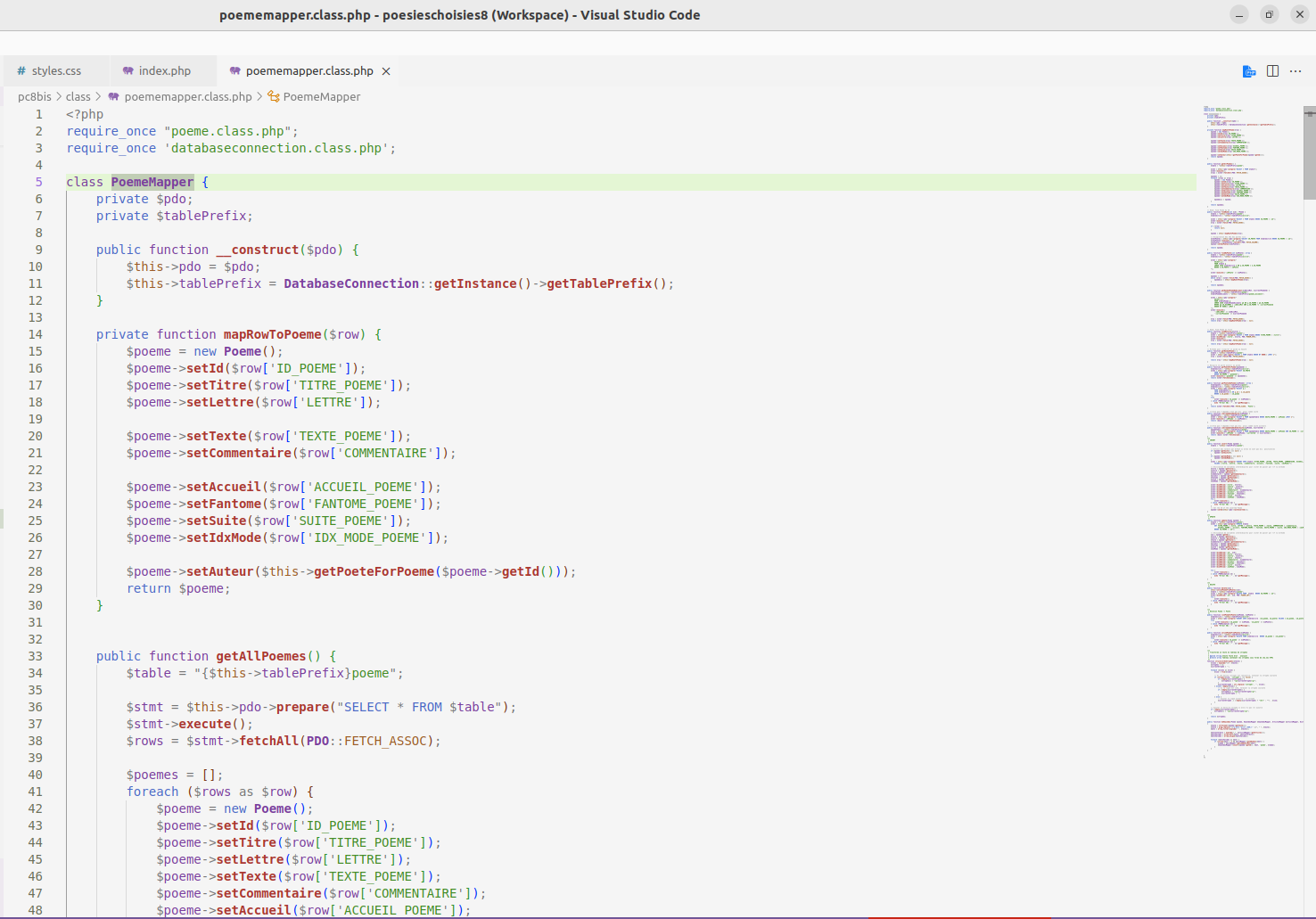
Une fenêtre Visual Studio Code avec le fantôme du code
[1] 2 à la puissance 7, le nombre de combinaisons de 0 et de 1 quand on dispose de 7 emplacements.
[2] Le 127e code étant un caractère invisible signifiant DEL, le caractère suppression, passons.
[3] codage universel de toutes les langues écrites du monde (110 000 signes), il est codé sur 16 bits et non plus 8
[4] qui stockait un nombre limité de mots à ne pas considérer, adverbes, déterminants, mots courts, dans un seul champ d’une seule table.